


生成AIが出力した作品が著作権を侵害していたとき、その責任を負うのは誰なのか。
早稲田大学法学学術院教授で『AIと著作権』などの著書も出版している上野達弘さんへのインタビュー。「学習」について焦点をあてた前編につづき、後編ではAIによる「生成」の課題を深掘りする。
著作権侵害になるかどうかの判断基準や、AIを使用する人が意識するべきこと、クリエイターの権利をどう守るべきかについて、話を聞いた。

上野達弘さん / 1971年、東京生まれ。京都大学法学部卒、同大学大学院法学研究科博士課程単位取得退学。成城大学法学部専任講師、立教大学教授を経て、2013年より現職。専門は著作権法を中心とする知的財産法。主著に『著作権法入門』(共著、有斐閣)、『AIと著作権』(共著、勁草書房)など。
生成AIによる作品が、既存作品の著作権侵害となりうるケースとは?
―たとえば、生成AIが出力したものが、既存の著作物に類似していて、著作権侵害を問われる可能性もあると思います。そのような類似性をどう見極めるのかについては、文化庁の委員会文書で示されたのでしょうか?
上野:もし生成AIが出力したものが著作権侵害にあたると、AIを使う人も、提供する人も、あるいはAIを開発する人も法的な責任を負う可能性があります。生成AIの利用にはリスクがつきまとうことを理解する必要があるかと思います。
その上で、著作権侵害だと認定されるためにはご指摘のように「類似性」が必要ですが、それに加えて「依拠性」が必要です。
依拠性とは、自分の著作物が他人の著作物に基づいてつくられたものだということです。したがって、他人の著作物に基づくことなく独自に作成したという場合は、依拠性がないため、たとえ他人の著作物とまったく同じものだったとしても著作権侵害になりません。
しかし、この依拠性の具体的意味がAIに関連して議論になっています。つまり、学習元コンテンツのなかに他人の著作物が入っていたというだけで、すべての学習元著作物について「依拠している」と言えるのかどうか、という点をめぐって論争があります。人が見聞きするのと、機械が学習するのとでは違いがあるのではないか、機械は人と違って一度学習した物を忘れないのではないかといったかたちで、いまも議論が続いています。
その結果、文化庁の「考え方」(*1)のなかでは、「原則依拠性を認めるしかない」という趣旨の考えが記述されていますが、他方で、つねに依拠性があると言えるかどうかは課題になるというような書き方がされています。
他方、「類似性」については、「考え方」でも明確な指針は示されていません。したがって、曖昧なままとも言えます。
なぜかというと、既存の著作物と類似しているかどうかという問題はAIに限って起きるわけではなく、人間がつくったものについても起きるからです。そして、著作権侵害の要件としての類似性は、AIが生み出そうが人間が生み出そうが同じ問題で、その判断にも違いはありません。ですから、今回の「考え方」にも具体的な基準が示されているわけではないのです。
作品の「類似性」はどう判断されるか
―AIがつくったものと人間がつくったもので類似性の判断が変わることはないというご指摘は、その通りだと思いました。
上野:類似性に関して従来から言われているのは、いわゆる「アイデア・表現二分論」というものです。著作権は具体的な表現を保護する一方で、アイデアやスタイル、作風、画風、世界観といったものは抽象的すぎて、著作権による独占にはふさわしくないため、著作権法上は自由だという原則です。
例えば「ディズニーのスタイル」というものがディズニーによって独占されてしまったら、表現が萎縮してしまいます。そうしたスタイルは、著作権法上自由だったからこそ文化が発展してきたと考えられます。

東京ディズニーランドの写真 / Shutterstock
上野:手塚治虫の『ジャングル大帝』があったからディズニーの『ライオン・キング』ができたかもしれないし、黒澤明監督の作品が『スター・ウォーズ』シリーズに影響を与えたのではないかとか、芸術や表現は影響しあってさらに発展していく。スタイルは著作権で独占させず、フリーだからこそ新しい作品が生み出されるという、世界中で異論なく共有されている考え方です。
手塚治虫原作の『ジャングル大帝』(1965)
アニメーション映画『ライオン・キング』の予告
上野:したがって、類似性というのは、抽象的なスタイルではなく、具体的な表現の共通性があるかどうかで判断することになりますが、表現とアイデアの区別が微妙なのもたしかです。訴訟でも一審と二審で結論が変わったり、学説がわかれたり、さらに国によって違ったりもします。そんな類似性判断について、今回の「考え方」が明確な方向性を示すことは到底無理ですし、また適切でもないように思います。
私も『著作物の類似性判断』という本を2021年に出して、分野毎に過去の裁判例を網羅的に紹介・分析しているんですが、結構判断が分かれていて、必ずしも一貫性があるように見えないこともあるんですよね。時代によって変化しているように見えることもあります。
このように類似性というのはどうしても不明確なところが残るのですが、実務の現場で、判断に困ることも多いかと思いますので、せめて過去の裁判例を紹介して、この事件ではこんな判断がされましたということを示しているわけです。
―類似性の判断は判例を見ていくしかないんですね。
上野:はい。もちろん、判例を見ても明確な判断基準を持つことまでは難しいかと思うのですが、判断の参考にはなるかと思います。
類似性の判断基準を明確にすべきだという考えもあるかもしれませんが、できたとしても望ましくないように思います。たとえば音楽なんかでも、3小節までだったら似ててもOKというルールが考えられますが、たしかに明確だとしても、それでは硬直的すぎてつねに適切とは言えないですよね。
その上で、著作権侵害というのは、これが認められるとものすごく重たい責任が課せられます。損害賠償や差し止めだけではなく、懲役10年以下の刑事罰が科せられることもあります。あまりにも簡単に類似性が認められてしまいますと、クリエイターの創作の自由が制約されてしまいます。ですので、類似性というのは、表現の自由という観点から、慎重に判断する必要があります。裁判所もバランスをとりながら慎重に判断していると思います。
AIを使う人が引き受けなければいけない「リスク」

OpenAIが2024年2月に発表した動画生成AIモデル「Sora」のデモ動画。テキストでプロンプトを入力すると、最大1分間の高品質動画を生成できる。 / OpenAIの公式サイトより
―すでにAIを活用している人も多いと思います。AIを使う上で、著作権という観点から意識するべきことはありますか?
上野:先ほど述べましたように、生成AIを使う人はそれなりのリスクを負って使う必要があると思います。
ある生成AIを使っていて、その生成AIが過去に学習したコンテンツのなかに入っている画像と同じものが出力されたとしても、AIを使っている人にはわからないですよね。それを本の表紙にして出版した段階で初めて判明して、学習元著作物の著作権者から訴えられたら、それ以降の出版は中止しなければならないことになります。
AIを操作した自分はそのことを知らなかったとしても、だからといって許されるものではないので、生成AIを使うということは、それだけリスクを引き受けることを意味するんだと思います。
─いまお話しされた例の場合のように、開発者側のみに責任があるわけではないんですね。
上野:AIを使う人、AIサービスを提供した人、AIを開発した人がいるとして、全員が責任を負う可能性があるわけです。一番可能性が高いのは最終的な利用者です。
それが怖くて生成AIを使わないという人がいるのも困りますので、Adobeなどは著作権侵害のリスクを低減したAIサービスを提供していて、もし顧客に法的な責任が生じた場合には補償することを表明しています。このように、AIサービス提供者や開発事業者が利用者のリスクを負担するという動きはこれからも出てくるかもしれないですね。
また最近の画像生成AIは、たとえば「ピカチュウを抱っこした女の子の絵を描いて」と指示しても、ピカチュウそのままの画像が出てこないようになっているものが増えています。なぜピカチュウを描いてくれないのかと聞くと、著作権の問題があって……などと答えたりもします。
最近では、生成AIが他人の著作物と類似性のあるようなコンテンツを出さないようにフィルタリングする技術が開発されつつあります。このような技術は今後発展していくと思うので、そうした技術による対応をしていないAI事業者はむしろ責任を問われるようになっていくかもしれません。
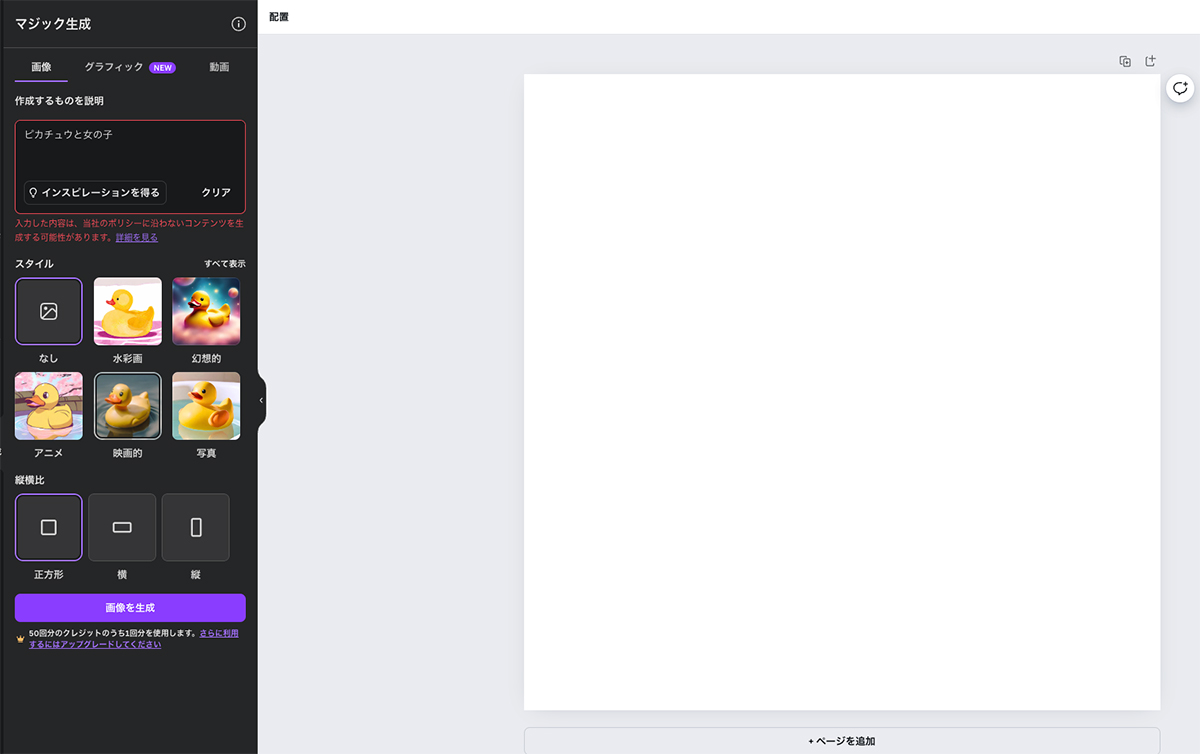
画像生成AIも活用できるビジュアル作成ツール「Canva」で「ピカチュウと女の子」というテキストを入力して画像を生成すると、「入力した内容は、当社のポリシーに沿わないコンテンツを生成する可能性があります」との警告が表示された。
生成AIの健全な発達のために必要なこと
─著作権侵害の責任を誰が負うのかという点は、議論の最中にあり、まだまだ課題があるということですね。
上野:開発事業者、サービス提供者、利用者。それらがどこまで責任を負うのかというのは、今回の「考え方」でも問題提起されていたかと思いますが、まだ不明確な点があります。
いずれにしても、今後の生成AIの健全な発達のためには、さっきみたいな技術的な措置がこれから重要になるんじゃないかなと思います。
内閣府の知的財産戦略本部が最近中間まとめ(*2)を出しましたが、そこでもAI問題については、三つの観点で取り組むべきだと言っています。
一つ目は「法律」で、法律やその解釈がもちろん重要です。この点、少なくとも著作権法については、基本的に整備されていると思います。
二つ目はAIが違法有害なコンテンツを出力することを抑制・防止する「技術」の観点です。ここでは、著作権侵害だけでなく、わいせつや児童ポルノ、拳銃、違法薬物、個人情報など様々な違法有害な出力について、これをブロックする技術の開発が進められるべきです。
三つ目が「契約」で、クリエイターや新聞社がAI事業者と協力して契約するということが考えられます。
もちろん情報解析規定があるので、AI事業者は、大量の雑誌を購入して、これをスキャンして機械学習することは可能かもしれないけれども、そんな手間なことをするより、出版社と契約して、情報解析に適したデジタルデータの提供を受けて学習を行なうことでウィンウィンの関係を築くことが可能です。このように、学習に適したデータの提供契約が今後ますます重要になると思いますし、実際に出版社など、そのような取り組みをしている事業者も出てきているようです。
このように、「法律」「技術」「契約」という三つの観点で今後ものを考えていくべきじゃないかというのが、最近の展望の一つです。
OpenAIが発表した「Sora」のデモ動画 / OpenAIのYouTubeチャンネルより
二次創作が盛んな日本。生成AIの作品が受け入れられづらいのはなぜ?
―もう一つ聞きたいことがあります。日本では『アトム』や『ドラえもん』などが人気なように、ロボットは慣れ親しんだ存在で、AIに対してポジティブな国ではないかという意見があります。また、日本は二次創作が広く受け入れられていて、文化が発展していると感じます。しかし、AIによってつくられた作品や、特定の著作物の「二次創作」に拒否感を持ったり問題視したりする人も多いように感じます。この違いはなぜなのか、上野さんが考えられていることがあれば教えてください。
上野:たしかに、日本ではロボットに対するネガティブなイメージはないとよく言われますよね。一方で、AIが生み出したコンテンツの商業利用に批判が寄せられることも多い。例として、2023年に集英社が売り出したAIのグラビアアイドル「さつきあい」の写真集は批判が殺到し、すぐに販売停止になったようです。
他方では、ご指摘のように日本では二次創作が発展していて、非常に寛容な社会でもあります。諸外国から見れば二次創作が黙認されているどころか、ビッグビジネスにもなっている日本の状況は不思議で、学問的にも興味深い現象に見えるようです。しかし同時に、生成AIの利用や開発に反発する声も小さくない。

「コミックマーケット103」が開催された東京ビッグサイト
上野:これはなぜかと考えたとき、二次創作文化は新しいクリエイターを育ててきたという歴史やエコシステムがあるからではないかと思います。
AIによる生成というのは、いくらやっても若いクリエイターや次世代の育成にはつながらない。生成AIの活用によって制作現場は効率化されるかもしれないけれども、そのようにして次世代のクリエイターが育たないままだと、将来的に業界が回らなくなってしまうかもしれません。そういう意味で、私はAI時代におけるクリエイター育成というものを考えていかなくてはいけないのではないかと思っています。
ただ、だからといってAI学習のための著作物利用を規制すべきだとは思いません。たとえAI学習を著作権で禁止できるようにしたとしても、生成AIは今後も発展を続けると考えられますので、解決にはなりません。ですので、私はAI学習を著作権法上自由とする日本法は維持すべきだと考えていますが、文化政策として何もしなくていいと思っているわけではありません。著作権制度としても、たとえば、生成AI事業者からクリエイターに正当な利益を分配する補償金制度を導入することも選択肢になるでしょう。
そうした制度がうまく働くかどうかはわからないし、そもそも文化の育成はすごく難しい。日本の文化予算は、国際的に見ても非常に限られていますので、そこから変えていく必要があるのかもしれません。ただ今後は、AIがもたらす社会的な便益を踏まえて、クリエイターへの利益分配はもちろん、クリエイターの育成など文化振興を実現する新しい仕組みの構想を検討すべきではないかと私は思っています。
―なるほど。AIと著作権の問題について、理解が深まりましたし、技術の発展と芸術文化やクリエイターの権利保護、両方のバランスを取りながら考えていくべきではないかと思いました。お話をしていただいて、本当にありがとうございました。
*1 文化庁 文化審議会著作権分科会法制度小委員会「AIと著作権に関する考え方について」
*2 内閣府 AI 時代の知的財産権検討会「AI 時代の知的財産権検討会 中間とりまとめ」
- プロフィール
-

- 上野達弘
-
1971年、東京生まれ。京都大学法学部卒、同大学大学院法学研究科博士課程単位取得退学。成城大学法学部専任講師、立教大学教授を経て、2013年より現職。専門は著作権法を中心とする知的財産法。主著に『著作権法入門』(共著、有斐閣)、『AIと著作権』(共著、勁草書房)など。
関連記事



- フィードバック 29
-
新たな発見や感動を得ることはできましたか?
-
